
I'm a visual learner; I really like to see ideas to be able to understand them. Back in university when I was writing exams, I would often be able to recall where on the page in the textbook I had seen the information needed, what pictures/graphs were around it, and to some degree visualize where I was when I learned it.
On the flip side, I'm very much less so an auditory learner. Take for example if I meet someone new with an unusual name, I struggle to understand it until I ask them to spell it out so that I can picture the letters in my head or, even better, write them down. It just doesn't seem to click otherwise.
Long story short, I like to get ideas down on paper.
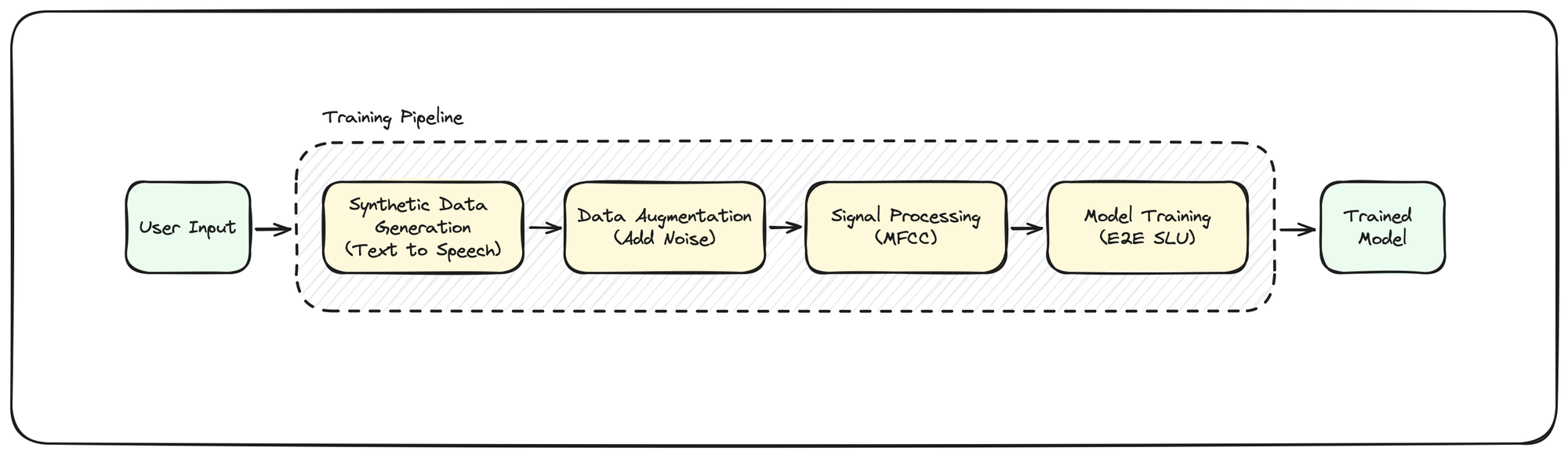
An open-source machine learning pipeline to train use case specific end-to-end spoken language understanding (E2E SLU) models for resource constrained devices.
Above you can see a simple overview of the model training flow I have in mind:
- Ingest user provided input, likely in a JSON or CSV file, about the utterances, intents, and slots
- Generate a synthetic dataset of WAV files using a text-to-speech model
- Augment these audio files to mix in noise and other sounds that are representative of the environment for the final use case
- Perform digital signal processing, likely by calculating the MFCC of the audio signal
- Train an E2E SLU model (woohoo!)
- Provide trained model output to user
I'm not entirely sure where the research contribution for my thesis will be yet. I imagine it will be somewhere in the model development and how to ensure it runs on a resource constrained device. There could also be some papers along the way. Perhaps something about generating the synthetic dataset?
Discussion